In this video, I'll give you 5 data projects you can take on to prove to prospective employers that you know your stuff!
1. Data Pipeline for ETL Process
Objective: Build a complete ETL (Extract, Transform, Load) pipeline that ingests data from multiple sources, transforms it, and loads it into a data warehouse.
Technologies: Python, Apache Airflow, SQL, AWS S3, AWS Redshift
Description: Create a data pipeline that extracts data from public APIs, CSV files, or databases. Apply transformations using Python or SQL and load the cleaned data into a data warehouse like AWS Redshift. Use Apache Airflow for orchestration and scheduling.
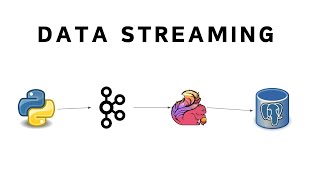
2. Real-Time Data Streaming
Objective: Develop a real-time data streaming application to process and analyze data on the fly.
Technologies: Apache Kafka, Apache Flink or Apache Spark Streaming, Python, Docker
Description: Set up a Kafka cluster to ingest streaming data from sources like IoT devices or social media APIs. Process the data using Apache Flink or Spark Streaming, and store the results in a NoSQL database like Cassandra. Dockerize the entire setup for easy deployment.
3. Data Warehouse Design and Implementation
Objective: Design and implement a data warehouse for a fictional e-commerce company.
Technologies: SQL, Snowflake or Google BigQuery, dbt (data build tool)
Description: Design a star or snowflake schema for the data warehouse, considering different data sources such as sales, inventory, and customer data. Implement the schema in Snowflake or BigQuery, and use dbt to automate the transformation and loading processes.
4. Machine Learning Pipeline
Objective: Create an end-to-end machine learning pipeline from data ingestion to model deployment.
Technologies: Python, Apache Airflow, scikit-learn, TensorFlow or PyTorch, Flask or FastAPI
Description: Build a pipeline that ingests data, preprocesses it, trains a machine learning model, and deploys the model as an API. Use Apache Airflow for orchestrating the pipeline, scikit-learn for model training, and Flask or FastAPI for serving the model.
5. Data Quality and Monitoring Dashboard
Objective: Implement a data quality and monitoring dashboard to track the health of data pipelines.
Technologies: Python, SQL, Grafana, Prometheus, Apache Airflow
Description: Develop scripts to perform data quality checks and generate metrics such as data completeness, accuracy, and timeliness. Use Apache Airflow to schedule these checks, Prometheus to collect metrics, and Grafana to visualize them in a dashboard.









Информация по комментариям в разработке