Learn how to easily clean your email addresses in a Pandas DataFrame by removing unwanted strings and keeping your data organized and valid.
---
This video is based on the question https://stackoverflow.com/q/62883209/ asked by the user 'Boomer' ( https://stackoverflow.com/u/11045591/ ) and on the answer https://stackoverflow.com/a/62898415/ provided by the user 'RamWill' ( https://stackoverflow.com/u/12148778/ ) at 'Stack Overflow' website. Thanks to these great users and Stackexchange community for their contributions.
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: search series values for substring, if found remove string and leave value blank
Also, Content (except music) licensed under CC BY-SA https://meta.stackexchange.com/help/l...
The original Question post is licensed under the 'CC BY-SA 4.0' ( https://creativecommons.org/licenses/... ) license, and the original Answer post is licensed under the 'CC BY-SA 4.0' ( https://creativecommons.org/licenses/... ) license.
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Remove Invalid Email Entries from DataFrame Using Pandas
When working with data, particularly in columns that contain email addresses, it’s common to encounter various invalid entries—like placeholders indicating "not available," such as 'n/a', 'N/A', or other similar formats. If you’ve found yourself needing to clean up this data, you're not alone. In this guide, we’ll walk through a systematic approach to identify and remove any invalid email entries from a Pandas DataFrame.
The Problem
Imagine you have a dataset with a column of email addresses. Unfortunately, this column contains various placeholders and invalid email formats that you need to clear out for better data integrity. Your criteria for invalid entries might include:
Typical placeholders like 'n/a', 'nA', and 'N/A'.
Various malformed email formats, such as 'na@ na.com', 'a@ na', or 'n@ n'.
Your goal is to remove these entries while preserving the valid email addresses, leaving those cells blank.
The Solution
Step 1: Set Up Your Environment
To start, ensure you have the necessary libraries. You’ll need pandas, which is a powerful data manipulation library in Python.
[[See Video to Reveal this Text or Code Snippet]]
Step 2: Define Your Keywords
Next, create a set of keywords representing the invalid email entries you want to remove. Using a Set here instead of a tuple allows for faster membership checking.
[[See Video to Reveal this Text or Code Snippet]]
Step 3: Create Your DataFrame
Now, let’s make a sample DataFrame that mimics your data scenario.
[[See Video to Reveal this Text or Code Snippet]]
Step 4: Cleanse the Data
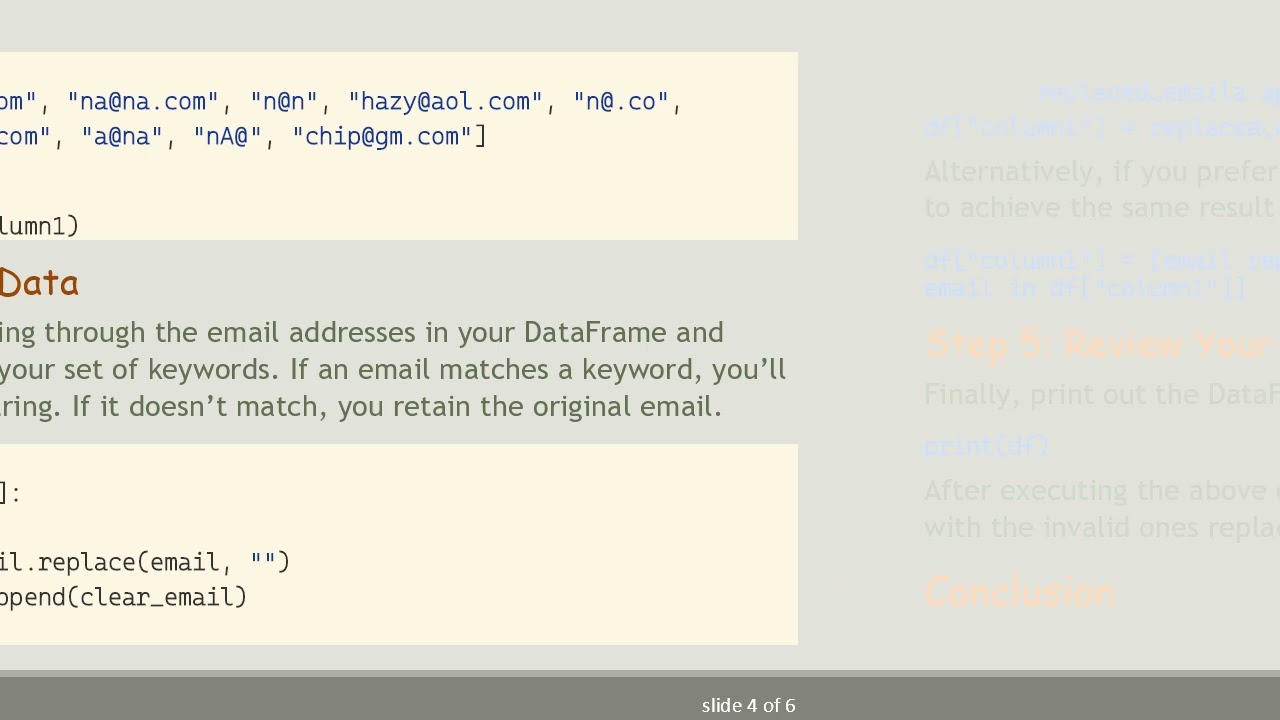
Here’s the key step—iterating through the email addresses in your DataFrame and checking each one against your set of keywords. If an email matches a keyword, you’ll replace it with an empty string. If it doesn’t match, you retain the original email.
[[See Video to Reveal this Text or Code Snippet]]
Alternatively, if you prefer a more compact solution, you can use list comprehension to achieve the same result in one line:
[[See Video to Reveal this Text or Code Snippet]]
Step 5: Review Your Data
Finally, print out the DataFrame to see the results of your cleansing operation.
[[See Video to Reveal this Text or Code Snippet]]
After executing the above code, your DataFrame will display the valid email addresses with the invalid ones replaced by blank spaces.
Conclusion
Cleaning up a DataFrame to remove invalid entries can greatly enhance the quality of your data analysis. With the steps outlined above, you now have a clear and efficient method to clear out unwanted email entries in Pandas. If needed, consider validating user input to ensure that only valid addresses are entered in the future, keeping your dataset cleaner right from the start.
With this approach, your data remains organized, and you can focus on further analysis without being bogged down by irrelevant entries. Happy data cleansing!





















Информация по комментариям в разработке