Data Engineering Mock Interview - First Round
Join Ankur Ranjan, an experienced Data Engineering professional with over 5 years of experience, and Aastha for an exciting and informative Data Engineering mock interview session.
If you're preparing for a Data Engineering interview, this is the perfect opportunity to enhance your skills and increase your chances of success. The mock interview simulates a real-life scenario and provides valuable insights and guidance. The topics covered include discussion on SQL vs NoSQL, Git Practices, Deployment methodology in the Data Engineering etc.
It covered questions from Apache Spark, SQL, Airflow, File Formats, AWS technology like SQS, SNS, Step Functions, Lambda Functions, AWS Glue, #aws Athena, EMR clusters, data modelling, database technologies, cloud platforms, and more. You'll get to see how professionals tackle technical questions and problem-solving challenges in a structured and efficient manner.
By watching this mock interview, you'll learn effective strategies to approach technical questions and problem-solving scenarios, gain familiarity with the data engineering interview process and format, enhance your communication skills and ability to articulate your thoughts clearly, identify areas of improvement, receive expert feedback on your performance, boost your confidence, and reduce nervousness for future interviews.
This mock interview suits all levels of experience, whether you're a fresh graduate, a career changer, or a seasoned professional looking to improve your interview skills. Don't miss out on this invaluable learning experience! Subscribe to our channel and hit the notification bell to be notified when the mock interview is released. Stay tuned for a deep dive into the world of data engineering.
Subscribe now and be the first to watch the Data Engineering Mock Interview with Ankur & Aastha.
🔅 To book a Mock interview - https://topmate.io/ankur_ranjan/15155
🔅 LinkedIn - / thebigdatashow
🔅 Instagram - / ranjan_anku
🔅 Ankur(Interviewer) 's LinkedIn profile - / thebigdatashow
🔅 Aastha (Interviewee)'s LinkedIn profile - / aastha-jain-851ab3140
Chapters:
00:00 - Introduction
04:54 - What is a fact and dimension table? And what is the difference between fact & dimension?
06:33 - What is the difference between row base file format & columnar file format? And why columnar-based file formats such as parquet or orc are favoured for analytics?
08:00 - Different compression techniques such as snappy, biz2 and LZO. And which one to choose?
08:20 - What is the write-ahead log?
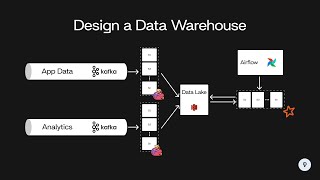
09:19 - When do we need to choose DataLake and when to use DataWarehouse
10:41 - What is the difference between #datalake & #datawarehouse ?
11:38 - Difference between RDD, Dataframe & Dataset
12:28 - Difference between SparkSession & SparkContext
12:57 - Pyspark optimisation technique
16:35 - Spark is an in-memory compute engine then why do we need cache in #apachespark ?
17:20 - Difference between cache and persist
19:55 - Lazy evaluation in Pyspark
22:53 - What are SQS and SNS in AWS?
24:00 - What is the work of Step functions in #aws?
25:40 - Use of AWS Glue
27:28 - How do you decide which should go to the Data Warehouse and which should be treated as an external table?
28:29 - How do you choose the database?
29:47 - What is elastic search?
31:18 - SQL Question
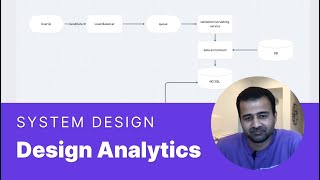
32:48 - System Design Question in #dataengineering
56:00 - Review of interview & recommendations for systems design in Data Engineering
#dataengineering #interview #interviewquestions #bigdata #mockinterview








Информация по комментариям в разработке